Test auf Normalverteilung in SPSS
Einen Test auf Normalverteilung führen wir anhand eines beispielhaften Länderdatensatzes durch. Eine der enthaltenen Variablen ist die Wachstumsrate des Bruttoinlandsproduktes pro Kopf. Wir nehmen an, dass diese Variable für die spätere Anwendung eines statistischen Verfahrens normalverteilt sein sollte. Um diese Voraussetzung zu überprüfen, wird zunächst der Datensatz in das Programm geladen.

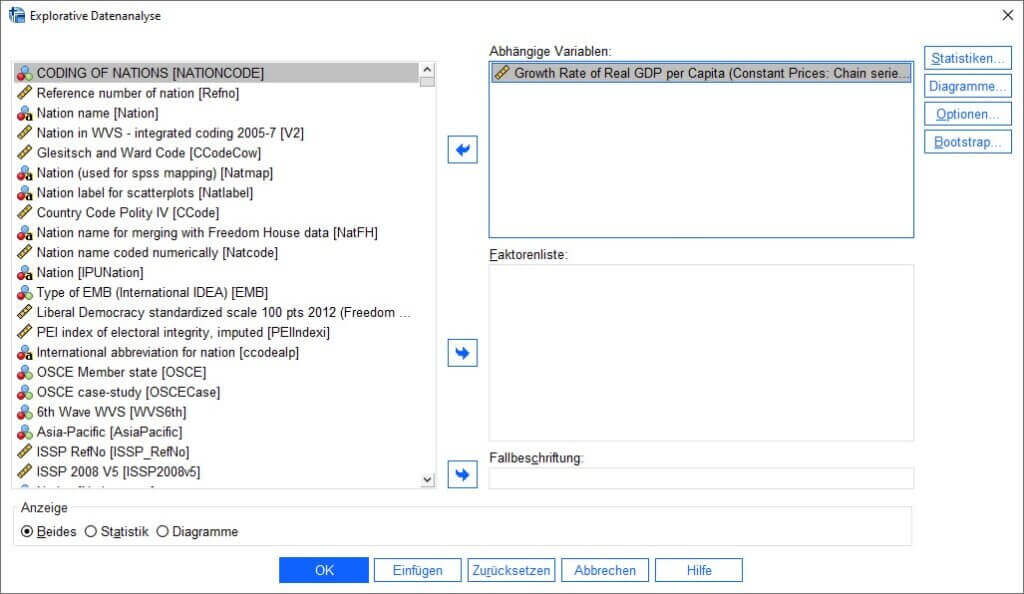
An die gewünschten Diagramme und statistischen Tests auf Normalverteilung gelangen wir über das Programmmenü, indem wir «Analysieren», «Deskriptive Statistiken» und schliesslich «Explorative Datenanalyse» wählen.

Nachdem sich das Dialogfeld «Explorative Datenanalyse» geöffnet hat, erkennen wir analog zu zahlreichen anderen Dialogfeldern in SPSS auf der linken Seite eine Liste der im Datensatz verfügbaren Variablen. Im ersten Schritt markieren wir in dieser Liste jene Variable, deren Verteilung wir überprüfen wollen, und verschieben sie mithilfe des oberen blauen Pfeils in das Feld «Abhängige Variablen». In diesem Fall handelt es sich um die Variable, die die Wachstumsrate des Bruttoinlandsproduktes pro Kopf (Gross Domestic Product/GDP per Capita) enthält.
Über das Feld «Faktorenliste» besteht die Möglichkeit, die gewünschten Statistiken und Tests nach bestimmten Gruppen im Datensatz aufzuschlüsseln. Bevor wir z. B. einen t-Test für unabhängige Stichproben durchführen, um Mittelwertunterschiede zwischen den Geschlechtern zu untersuchen, können wir zusätzlich das Geschlecht in die Faktorenliste aufnehmen. So könnten wir die Frage beantworten, ob die Normalverteilungsvoraussetzung der abhängigen Variable innerhalb beider Gruppen erfüllt ist.

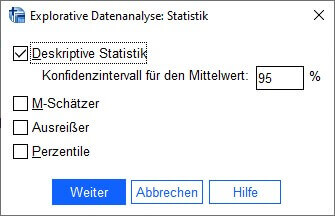
Über die Schaltfläche «Statistiken» besteht die Möglichkeit, sich deskriptive Statistiken der gewählten Variable ausgeben zu lassen. Wir lassen die Standardeinstellung unverändert, sodass das Häkchen bei «Deskriptive Statistik» aktiviert bleibt. Mit «Weiter» kehren wir zurück ins ursprüngliche Dialogfeld.

Zentral für die Prüfung auf Normalverteilung ist die nächste Schaltfläche «Diagramme». Hier können wir zunächst einstellen, welche Form eines Boxplots ausgegeben wird. Da wir lediglich eine abhängige Variable und keine Faktoren definiert haben, kann die Standardeinstellung «Faktorstufen zusammen» unverändert bleiben. Für unsere Zwecke relevanter sind die Kontrollkästchen unter «Deskriptive Statistik», wobei wir das Kontrollhäkchen bei «Histogramm» aktivieren. Über ein solches Histogramm haben wir eine zusätzliche Möglichkeit, die Normalverteilung der Variable zu beurteilen.
Darüber hinaus aktivieren wir das Kontrollkästchen neben «Normalverteilungsdiagramm mit Tests». Über diese Option erhalten wir neben den Tests auf Normalverteilung (Kolmogorov-Test und Shapiro-Wilk-Test) Normalverteilungsdiagramme in Form von Quantil-Quantil-Diagrammen (Q-Q-Diagramme). Schliesslich können wir die Auswahl mit einem Klick auf «Weiter» bestätigen und kehren damit ins ursprüngliche Menü zurück.

Da die übrigen Schaltflächen «Optionen» und «Bootstrap» für eine Überprüfung der Normalverteilung nicht benötigt werden, sind alle notwendigen Einstellung vorgenommen und wir können mit einem Klick auf «OK» die Ausgabe produzieren.
Die Ausgabe beginnt mit einer Zusammenfassung der Fallverarbeitung, sodass die Anzahl der gültigen und fehlenden Fälle resümiert wird. Die folgende Tabelle «Deskriptive Statistik» enthält eine Vielzahl statistischer Kennzahlen, die teilweise bereits Hinweise zur Beurteilung der Normalverteilung enthalten. So ist in diesem Fall der Median kleiner als der Mittelwert, was auf eine leicht linkssteile (rechtsschiefe) Datenverteilung hindeutet.
Die Symmetrie der Verteilung kann zusätzlich mit der Schiefe beurteilt werden, die separat ausgewiesen wird. Je symmetrischer eine Verteilung ist, desto stärker nähert sich der Wert 0 an. Ist die Verteilung linkssteil (rechtsschief), so nimmt die Kennzahl wie im vorliegenden Fall ein positives Vorzeichen an. Eine rechtssteile (linksschiefe) Verteilung würde zu einem negativen Vorzeichen führen.
Eine weitere ausgewiesene Kennzahl mit Relevanz für die Beurteilung der Normalverteilung ist die Kurtosis. Die Kurtosis gleicht die Randverteilung der ausgewählten Variable mit der Normalverteilung ab. Im Sinne der Voraussetzung der Normalverteilung ist auch hier ein Wert nahe 0 wünschenswert. Auch die Kurtosis kann ein negatives oder positives Vorzeichen annehmen. Sind die Randbereiche stärker als bei einer Normalverteilung ausgeprägt, erhält man ein positives Vorzeichen. Umgekehrt wird das Vorzeichen negativ, wenn wir Randverteilungen haben, die schwächer sind als bei einer Normalverteilung zu erwarten.
Zuletzt deutet die Standardabweichung darauf hin, dass sich die Werte um die Mitte der Verteilung häufen und somit eine Normalverteilung vorliegen könnte. Eine abschliessende Beurteilung ist jedoch erst nach Betrachtung der folgenden Ausgabe möglich.
Konkret folgt nun die Tabelle «Test auf Normalverteilung», die die Ergebnisse des Kolmogorov-Tests und Shapiro-Wilk-Tests enthalten. Dabei interessieren wir uns vor allem für die Signifikanzwerte. Sind die Werte p < .05, so müssen wir die Nullhypothese der Normalverteilung wie im vorliegenden Fall ablehnen.

Auch anhand der folgenden Diagramme können wir mögliche Ursachen für die Testergebnisse des Kolmogorov-Tests und Shapiro-Wilk-Tests näher beleuchten. Dargestellt werden Histogramm, Q-Q-Diagramme sowie ein Boxplot. Nach Betrachtung der Diagramme wird die Ursache für die Testergebnisse deutlich. Demnach sorgen wenige Datenpunkte am oberen Ende der Verteilung dafür, dass die Annahme der Normalverteilung verletzt ist. Trotzdem kommt die Verteilung laut Histogramm und Q-Q-Diagrammen einer Normalverteilungskurve recht nahe.
Für die weiteren Analysen besteht also die Möglichkeit, die Datenausreisser zu identifizieren und auszuschliessen, um die Normalverteilung zu gewährleisten. Der Boxplot weist diese Ausreisser gesondert mit Fallnummern aus, sodass man diese Fälle vor Beginn der nächsten Analyseschritte leicht ausschliessen kann.
Die gezeigte Ausgabe wird mithilfe des folgenden Befehls alternativ über die Syntax produziert. Mit «EXAMINE VARIABLES» wird die Ausgabe einer explorativen Datenanalyse eingeleitet, bevor der Variablenname spezifiziert wird (hier: EconGrowth). Mit den folgenden Zeilen legt man fest, welche optionalen Tests und Diagramme das Programm ausgeben soll.
EXAMINE VARIABLES=EconGrowth
/PLOT BOXPLOT HISTOGRAM NPPLOT
/COMPARE GROUPS
/STATISTICS DESCRIPTIVES
/CINTERVAL 95
/MISSING LISTWISE
/NOTOTAL.